|
|
Working Group on Knowledge Discovery and
Management
COST Action 282 |
|||
Main Goals
Network
Members Network Map Agenda
Participants Short Missions Coordinators
|
|
|
||
HEADLINES
-------------------------------------------- NEWS for those attending the Group First Meeting in
Coleraine. -------------------------------------------- Group First Meeting
24-25 May 2002 Werner Dubitzky (Chairman) University of Ulster School of Biomedical Sciences, Cromore Road, Coleraine BT52 1SA, Northern Ireland Phone: +44-(0)28-70-324478, Fax: +44-(0)28-70-324965 |
||||
Main
Goals
|
||||
|
The importance of the area
of knowledge discovery and knowledge management
is evidenced by the increasing number of scientific works and events that
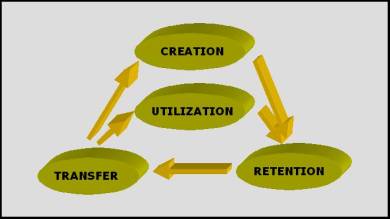
take place each year on this subject. Both science and industry communities have understood the importance of this area and are working on knowledge discovery and management (KD&M). According to the Knowledge Management Forum, an architecture for a KD&M system comprises: creation; retention; transfer and utilization of knowledge. This architecture is depicted in Fig. 1. |
||||
|
|
|
|
|
|
|
|
Fig. 1
Architecture for KD&M system. Knowledge discovery is a
fundamental task in knowledge creation and case-based reuse and maintenance
are important approaches for knowledge utilization and retention. The COST 282 working group
is devoted to research and application of knowledge discovery and case-based
techniques for KD&M. Some areas of application
interest within this group include but are not limited to:
Given the complexity of
the domains tackled, the data representation and knowledge representations
will be correspondingly more complex than those encountered by current
knowledge discovery algorithms. Domain knowledge will also
play an increasingly more critical part of the overall modeling. This working
group will look to the development of knowledge discovery and case-based techniques
that can incorporate domain knowledge and utilize it effectively during the
discovery of novel, non-trivial, and useful knowledge from related data sets.
As knowledge discovery and
utilization involve also important aspects concerning creative capabilities,
we are also strongly interested in developing synergies with COST282 WG4 on
Computational Creativity. Application Examples Life/biological Science Novel high-throughput
technologies such as DNA microarrays are generating an overwhelming plethora
of biological data. Classical statistical and data mining methods have not
been developed to address the specific requirements of life science
applications. First, the analysis of gene expression microarrays is hampered
by the high dimensionality of the feature space that often exceeds the sample
space dimensionality by a factor of 1,000 and more. Traditional statistical
and knowledge discovery methods and applications do not have this property.
Second, the fact that the gene expression data are very noisy represents
another challenge. Typical statistical and standard data mining are very
sensitive to noise. Third, most of the existing methods operate in
weak-theory domains, and thus have not adequate mechanism for effectively and
efficiently integrating background knowledge into the discovery process. The
life science community has accumulated huge amounts of background knowledge
most of which is accessible through the Internet in electronic format
(databases, information bases, knowledge bases, and document bases). The
challenge to integrate this information into an automated discovery process
is formidable, because of the physical (global on the Internet) and
conceptual distribution of the information, and because of the sheer scale of
available knowledge. Finally, despite the fact that artificial intelligence
methods are closely related to statistics and statistical principles, most
techniques do not address the life scientist's requirement for qualifying
analytical results by means of confidence measures or a p-values. Software Design Software design is a
complex activity that involves skills on software analysis, programming and
reuse. In general software designers do not start design from scratch. They
search for pieces of software useful for their task and adapt and integrate
them into a new application that in its way will constitute new knowledge
which will be integrated into a software library. It is a challenging
activity to discover the most suitable pieces of software (knowledge) for a
specific task and the most effective adaptation and reuse procedures in a
framework that is typical for a KD&M process. Within this working group
we intend to research methods and architectures suitable for KD&M on
software design. Geo-referenced Multimedia and Internet Multimedia data bases and
the Internet are probably some of the information sources for which the
problematic of KD&M is more evident. In this way much attention has been
devoted to the subject. One aspect that we want to
work on is the development of discovery and management algorithms for
heterogeneous sources of information (like multimedia and Internet) on the
presence of geo-referenced data (data comprising geographical information). We are particularly
interested on the application of these techniques to the domains of medicine
and biology. |
|||